Batch Change Handling¶
Overview¶
SynchDB periodically fetches a batch of change request from Debezium runner engine at a period of synchdb.naptime milliseconds (default 100). This batch of change request is then processed by SynchDB. If all the change requests within the batch have been processed successfully (parsed, transformed and applied to PostgreSQL), SynchDB will notify the Debezium runner engine that this batch has been completed. This signals Debezium runner to commit the offset up until the last successfully completed change record. With this mechanism in place, SynchDB is able to track each change record and instruct Debezium runner not to fetch an old change that has been processed before, or not to send a duplcate change record.
Batch Handling¶
SynchDB processes a batch within one transaction. This means the change events inside a batch are either all or none processed. When all the changes have been successfully processed, SynchDB simply sends a message to Debezium runner engine to mark the batch as processed and completed. This action causes offsets to be committed and eventually flush to disk. An offset represents a logical location during a replication similar to the LSN (Log Seqeuence Number) in PostgreSQL.
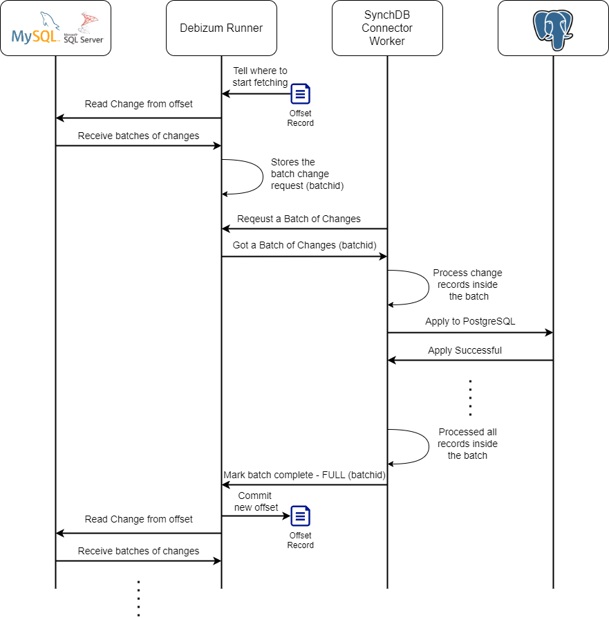
If a batch of changes are partially successful on PostgreSQL, it would cause the transaction to rollback and SynchDB will not notify Debezium runner about batch completion. When the connector is restarted, the same batch will resume processing again.