组件架构¶
SynchDB Worker 组件图¶
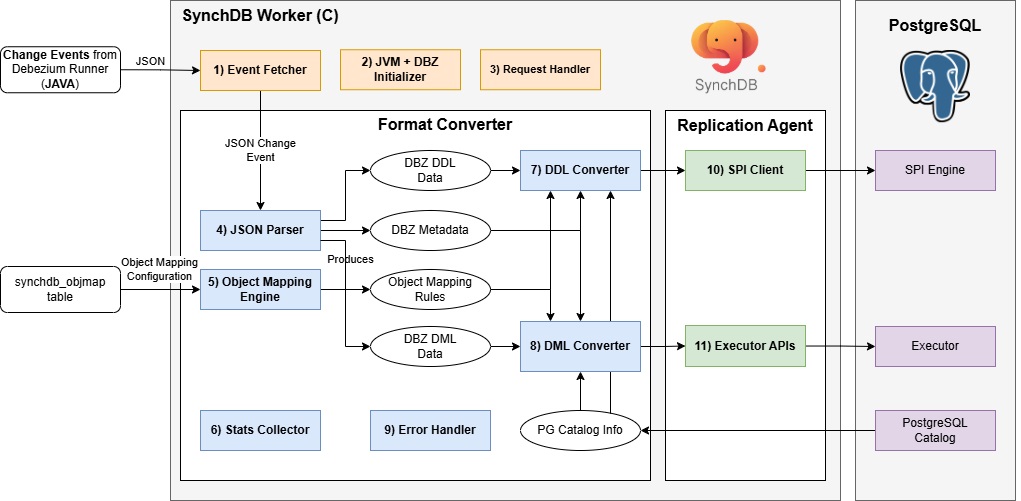
SynchDB Worker 是由 SynchDB 扩展发起和启动的 PostgreSQL 后台工作进程。它负责初始化 Java 虚拟机 (JVM),运行 Debezium Runner模块,(它是 SynchDB 的 Java 部分),利用嵌入式 Debezium 引擎从异构数据库源获取更改事件。每个 SynchDB 工作进程都由下面列出的组件和模块组成:
- 事件获取器
- JVM + DBZ 初始化程序
- 请求处理器
- JSON 解析器
- 对象映射引擎
- 统计信息收集器
- DDL 转换器
- DML 转换器
- 错误处理程序
- SPI 客户端
- 执行器 API
1) 事件获取器¶
事件获取器主要负责从运行在 JVM 中的嵌入式 Debezium Runner 获取一批 JSON 变更事件。此操作通过 Java 接口 (JNI) 库完成,通过定期调用 JAVA 函数返回一个 JAVA String 列表,该列表以 JSON 格式表示每个变更请求。此列表 表示一批 JSON 变更事件。再次调用 JNI 库来迭代此 List,将内容从 JAVA String 转换为 C 字符串,并将其发送到 4) JSON 解析器 进行进一步处理。获取频率可通过 synchdb.naptime 配置,批次的最大大小可通过 synchdb.dbz_batch_size 配置。
当批次完成时,即其中的所有更改事件都已处理完毕,它将通过 JNI 调用 markBatchComplete() JAVA 函数以指示此批次已成功完成。这将导致 Debezium Runner 提交并推进偏移量。有关批次管理的更多信息,请参见此处。
2) JVM + Debezium (DBZ) 初始化程序¶
JVM + DBZ 初始化程序主要负责实例化新的 JVM 环境并在其中运行 Debezium Runner (dbz-engine-x.x.x.jar)。此 .jar 文件默认安装在 pg_config 返回的 $LIBDIR 中。您也可以通过设置环境变量 DBZ_ENGINE_DIR 为 Debezium Runner .jar 文件指定备用路径。SynchDB 当前使用 JNI_VERSION_10 作为 JNI 版本,兼容 JAVA v10 至 v18。但是,将来我们可能会升级 JNI 版本以获得 JNI 的最新改进和优势。可以通过 synchdb.jvm_max_heap_size 配置分配给 JVM 的最大heap内存。如果设置为零,JVM 将自动分配理想的heap大小。
请注意,每个 SynchDB 工作进程都会初始化并运行一个 JVM 实例,因此运行的工作进程越多,所需的heap内存就越多。您可以通过调用 synchdb_log_jvm_meminfo('$connector_name') 函数查看 SynchDB 工作进程的 JVM 当前heap和非heap内存使用情况,内存摘要将记录在 PostgreSQL 日志文件中。
3) 请求处理器¶
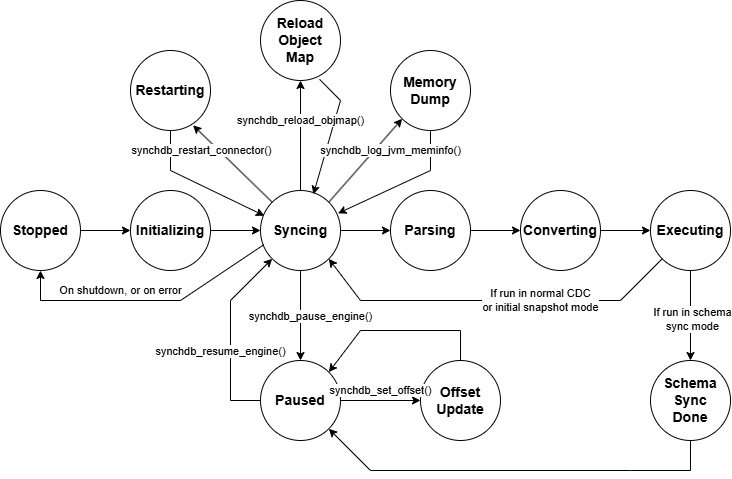
请求处理器主要负责检查和处理来自 SynchDB 用户的任何传入状态更改请求。此类状态更改请求的示例包括从“同步”到“暂停”,从“暂停”到“更新偏移”等。以下是 synchdb 的状态图。更多信息可以在 此处 找到。
4) JSON 解析器¶
JSON 解析器负责将传入的 JSON 更改事件解析为 SynchDB 可以使用的 C 结构。SynchDB 依赖 PostgreSQL 的原生 JSONB 解析器来满足所有解析和迭代需求。对于 DML JSON 事件,它首先解析 JSON 更改事件的“架构”部分(在本文档中也称为元数据),以了解 Debezium 如何表示用户数据。这包括每个字段的数据类型表示、值的比例……等等。然后,它解析“有效负载”以获取“之前”和“之后”的值。最后,它解析“源”部分以获取表名、数据库名称和数据来源的连接器类型。
对于 DML JSON 事件,将解析相同的部分,但“有效负载”下预期的属性不同。它解析“有效负载”下的“tableChanges”以了解指定表的列名、类型和其他属性。
根据操作的性质,生成的 C 结构数据随后被发送到 DDL Converter(用于 DDL 请求)或 DML Converter(用于 DML 请求)进行下一阶段的处理。以下是 JSON 事件中 DDL 和 DML“有效负载”的示例:
DML 有效负载:
{
"payload": {
"before": null,
"after": {
"id": 3,
"g": {
"wkb": "AQMAAAABAAAABQAAAAAAAAAAAAAAAAAAAAAAFEAAAAAAAAAAQAAAAAAAABRAAAAAAAAAAEAAAAAAAAAcQAAAAAAAAAAAAAAAAAAAHEAAAAAAAAAAAAAAAAAAABRA",
"srid": null
},
"h": null
},
"source": {
"version": "2.6.2.Final",
"connector": "mysql",
"name": "synchdb-connector",
"ts_ms": 1743631156000,
"snapshot": "last",
"db": "inventory",
"sequence": null,
"ts_us": 1743631156000000,
"ts_ns": 1743631156000000000,
"table": "geom",
"server_id": 0,
"gtid": null,
"file": "mysql-bin.000009",
"pos": 1026620577,
"row": 0,
"thread": null,
"query": null
},
"op": "r",
"ts_ms": 1743631156410,
"ts_us": 1743631156410423,
"ts_ns": 1743631156410423395,
"transaction": null
}
}
DDL 有效负载:
"payload": {
"source": {
"version": "2.6.2.Final",
"connector": "sqlserver",
"name": "synchdb-connector",
"ts_ms": 1728337635149,
"snapshot": "true",
"db": "testDB",
"sequence": null,
"ts_us": 1728337635149000,
"ts_ns": 1728337635149000000,
"schema": "dbo",
"table": "customers",
"change_lsn": null,
"commit_lsn": "00000195:000010a0:0003",
"event_serial_no": null
},
"ts_ms": 1728337635150,
"databaseName": "testDB",
"schemaName": "dbo",
"ddl": null,
"tableChanges": [
{
"type": "CREATE",
"id": "\"testDB\".\"dbo\".\"customers\"",
"table": {
"defaultCharsetName": null,
"primaryKeyColumnNames": [
"id"
],
"columns": [
{
"name": "id",
"jdbcType": 4,
"nativeType": null,
"typeName": "int identity",
"typeExpression": "int identity",
"charsetName": null,
"length": 10,
"scale": 0,
"position": 1,
"optional": false,
"autoIncremented": true,
"generated": false,
"comment": null,
"defaultValueExpression": null,
"enumValues": null
},
{
"name": "first_name",
"jdbcType": 12,
"nativeType": null,
"typeName": "varchar",
"typeExpression": "varchar",
"charsetName": null,
"length": 255,
"scale": null,
"position": 2,
"optional": false,
"autoIncremented": false,
"generated": false,
"comment": null,
"defaultValueExpression": null,
"enumValues": null
},
{
"name": "last_name",
"jdbcType": 12,
"nativeType": null,
"typeName": "varchar",
"typeExpression": "varchar",
"charsetName": null,
"length": 255,
"scale": null,
"position": 3,
"optional": false,
"autoIncremented": false,
"generated": false,
"comment": null,
"defaultValueExpression": null,
"enumValues": null
},
{
"name": "email",
"jdbcType": 12,
"nativeType": null,
"typeName": "varchar",
"typeExpression": "varchar",
"charsetName": null,
"length": 255,
"scale": null,
"position": 4,
"optional": false,
"autoIncremented": false,
"generated": false,
"comment": null,
"defaultValueExpression": null,
"enumValues": null
}
],
"comment": null
}
}
]
}
5) 对象映射引擎¶
对象映射引擎负责加载和维护每个活动连接器下的对象映射信息。这些映射信息告诉 SynchDB 如何在 DDL 和 DML 处理期间将源对象映射到目标对象。默认情况下,Synchdb 没有对象映射规则,它将使用默认映射规则来处理数据。
对象可以引用: * 表名。 * 列名。 * 数据类型。 * 转换表达式。
可以使用synchdb_add_objmap() 函数创建映射规则之前将源表名、列名和数据类型映射到不同的目标表名、列名和数据类型,并且可以通过查询synchdb_objmap 表来查看所有规则。有关对象映射的更多信息,请参见此处。在synchdb_att_view() 视图下可以查看哪些内容映射到哪些内容的摘要。
转换表达式 是一个 SQL 表达式,将在数据转换完成后、应用数据之前运行(如果指定)。此表达式可以是 PostgreSQL 中可运行的任何表达式,例如调用另一个 SQL 函数或使用运算符。有关对象映射规则的更多信息,请参见此处。
6) 统计收集器¶
统计收集器负责收集 SynchDB 自操作开始以来的数据处理统计信息。这包括 DDL 和 DML 的数量、已处理的 CREATE、INSERT、UPDATE、DELETE 操作数量、处理的平均批处理大小以及描述数据在源中首次生成时间、Debezium 处理数据的时间以及在 PostgreSQL 中应用数据的时间的几个时间戳。这些指标可以帮助用户了解 SynchDB 的处理行为,以调整和优化设置以提高处理性能。有关统计数据的更多信息,请参见此处。
7) DDL 转换器¶
DDL 转换器负责将“JSON 解析器”生成的 DDL 数据转换为 PostgreSQL 可以理解的格式。对于 DDL,SynchDB 依赖 PostgreSQL SPI 引擎进行处理,因此转换的输出是正常的 SQL 查询字符串。DDL 转换器检查 DDL 数据,并必须与“对象映射引擎”配合使用,以正确转换源和目标之间的表、列名称或数据类型映射。
如果要根据“对象映射引擎”将名为“employee”的远程表映射到目标中的“staff”,则 DDL 转换器负责解析这些名称映射并相应地为 SPI 创建 SQL 查询。
转换器目前可以处理以下 DDL 操作:
- 创建表 CREATE TABLE
- 删除表 DROP TABLE
- 更改表更改列 ALTER TABLE ALTER COLUMN
- 更改表添加列 ALTER TABLE ADD COLUMN
- 更改表删除列 ALTER TABLE DROP COLUMN
对于 CREATE 和 DROP,转换器能够从输入的 DDL 数据中为 SPI 创建相应的查询字符串。对于 ALTER、ADD 和 DROP COLUMN,转换器需要访问 PostgreSQL Catalog以了解现有表属性,并确定是否有要添加、删除或更改的列。Debezium 的 JSON 更改事件始终包含整个表的信息,并且不会明确指出已删除或添加的内容。因此,需要 DDL 转换器组件来找出此信息并生成正确的查询字符串。有关 DDL 复制的更多信息,请参见此处
8) DML 转换器¶
DML 转换器负责将“JSON 解析器”生成的 DML 数据转换为 PostgreSQL 可以理解的格式。对于 DML,SynchDB 依赖 PostgreSQL 的执行器 API 将数据直接应用于 PostgreSQL,因此转换的输出是 PostgreSQL 执行器可以理解的 TupleTableSlot (TTS) 格式。为了让 PostgreSQL 生成正确的 TTS,DML 转换器依赖于:
- 描述负载数据格式 DBZ 元数据
- PostgreSQL 目录 (pg_class 和 pg_type),用于了解目标表的信息、每列的数据类型和属性。
- 对象映射规则,用于确定是否需要在处理的数据上运行额外的转换表达式
- 要处理的数据
DML 转换器由几个例程组成,这些例程可以处理特定的输入数据类型并生成特定的输出类型。为特定转换场景选择正确的例程可能是一个挑战,因为某些数据类型可能是用户定义的,或者由 SynchDB 不太了解的其他扩展创建。SynchDB 必须设计为处理 PostgreSQL 中可能存在的本机和非本机数据类型。
例程选择首先查看在 PostgreSQL 中创建的数据类型,该数据类型可分为 2 种类型,每种类型的处理技术略有不同:
- 本机数据类型。
- 非本机数据类型。
处理本机数据类型¶
下图显示了受支持的本机数据类型列表以及 SynchDB 如何根据其性质(或类别)将它们分组在一起。例如,数字组包含所有本质上是数字的整数或浮点数据类型。如果数据包含非数字字符,它们将给出错误。同样,不同的数据类型组需要特定的数据格式才能应用。
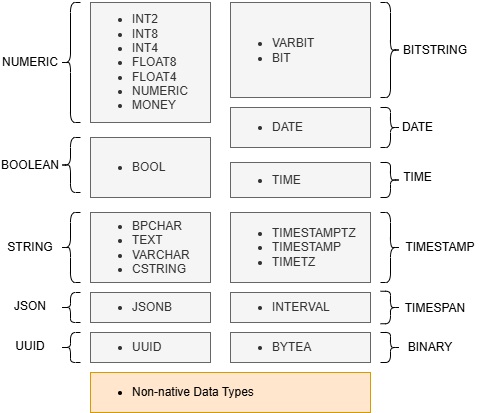
现在 DML 转换器知道如何在 PostgreSQL 端为这些受支持的本机数据类型生成数据,然后它会查看 DBZ 元数据以了解源数据的表示方式。这是必要的,因为 Debezium 引擎可能会对数据进行编码以打包更多需要在处理数据之前解码的信息,或者使用结构来表示复杂的数据类型,如几何图形。如果不知道 Debezium 如何表示数据,数据处理可能会产生不理想的结果,导致 PostgreSQL 在应用期间出错。以下是 Debezium 可以表示有效负载数据的格式类型列表:
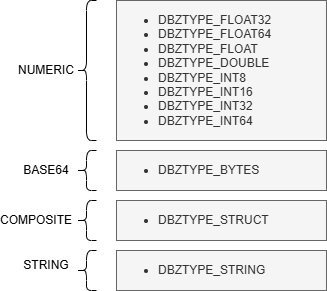
有了这两条信息,DML 转换器就知道输入是什么样子,输出应该是什么样子。它将从其函数矩阵中选择最佳处理程序来处理数据。例如,如果目标类型为“FLOAT4”,源数据类型格式为“DBZTYPE_BYTES”,则将选择函数“handle_base64_to_numeric()”来处理数据。所选函数负责解码二进制输入并将其计算为数字。
处理非原生数据类型¶
表可能包含由用户自定义创建或由另一个已安装的扩展创建的列数据类型。在这种情况下,上面提到的原生数据类型处理将不起作用,因为该类型未列在受支持的原生数据类型列表中。相反,DML 转换器会访问目录,获取非原生数据类型的 OID,并查找其在 PostgreSQL 中定义的“类别”。以下是截至版本 17 的 PostgreSQL 支持的类别列表:
#define TYPCATEGORY_INVALID '\0'
#define TYPCATEGORY_ARRAY 'A'
#define TYPCATEGORY_BOOLEAN 'B'
#define TYPCATEGORY_COMPOSITE 'C'
#define TYPCATEGORY_DATETIME 'D'
#define TYPCATEGORY_ENUM 'E'
#define TYPCATEGORY_GEOMETRIC 'G'
#define TYPCATEGORY_NETWORK 'I'
#define TYPCATEGORY_NUMERIC 'N'
#define TYPCATEGORY_PSEUDOTYPE 'P'
#define TYPCATEGORY_RANGE 'R'
#define TYPCATEGORY_STRING 'S'
#define TYPCATEGORY_TIMESPAN 'T'
#define TYPCATEGORY_USER 'U'
#define TYPCATEGORY_BITSTRING 'V'
#define TYPCATEGORY_UNKNOWN 'X'
类别会告诉 DML 转换器数据类型的性质(数字?字符串?日期时间?...等等),以帮助转换器选择正确的例程进行处理。在大多数情况下,使用类别与描述输入数据格式的 DBZ 元数据配对就足以选择正确的例程来处理数据。但是,在某些情况下,这可能还不够。例如,自定义 DATE、TIME、TIMESTAMP 日期类型都可以归类在 TYPCATEGORY_DATETIME 下,因此转换器不知道它是否正在使用 DATE、TIME 或 TIMESTAMP,因为每个类型都会产生不同的时间格式。目前,转换器会从数据类型名称中查找某些关键字来识别。将来,我们可能会公开这部分,让用户告诉转换器在出现歧义时应该使用哪个例程。另一个示例是 TYPCATEGORY_USER 和 TYPCATEGORY_GEOMETRIC,它们没有清楚地表明数据格式。对于这些类别,转换器目前不执行任何进一步处理,因为它只是将数据负载保持原样。PostgreSQL 可能会也可能不会拒绝此类未处理的数据。这就是为什么接下来的转换功能很重要,它为 DML 转换器提供了最后一次纠正其数据负载的机会。
数据转换¶
在输入数据通过上述逻辑处理后,转换器将检查用户是否已配置“转换表达式”,该表达式应在应用于 PostgreSQL 之前应用于已处理的数据。转换表达式可以是任何可以在 psql 提示符上运行的 PostgreSQL 表达式、命令或 SQL 函数。它使用“%d”作为占位符,在转换期间将替换为已处理的数据。例如,转换表达式“'>>>>>' || '%d' || '<<<<<'”将在已处理的字符串数据前面和后面添加其他字符。
因此,如果非本地数据类型具有 TYPCATEGORY_USER 类别,DML 转换器没有合适的例程来处理此数据并将保持原样,我们可以定义一个转换表达式来调用自定义 SQL 函数,它知道如何正确处理数据并生成合适的输出。例如,表达式“to_my_composite_type('%d')”将使用数据作为输入来调用用户定义的 SQL 函数“to_my_composite_type”。表达式必须具有返回值,因为它将在应用期间输入到 PostgreSQL 中。
9) 错误处理程序¶
错误处理程序主要负责处理数据同步每个阶段可能出现的任何错误。格式转换器支持多种错误处理策略,可通过“synchdb.error_handling_strategy”参数进行配置,可能的选项如下:
exit (默认)¶
这是默认的错误策略,当发生错误时,连接器工作器会退出。当前正在处理的导致错误的批次将不会被标记为已完成,并且不会提交同一批次中已成功完成的更改事件。用户应检查“synchdb_state_view()”或日志文件中返回的错误消息以解决错误。当连接器工作器重新启动时,连接器将自动重试之前失败的同一批。
retry¶
此策略为连接器工作器添加了 5 秒的“restart_time”,这会导致 PostgreSQL 的 bgworker 引擎在工作器退出时每 5 秒自动启动一次工作器。这意味着当发生错误时,连接器工作器仍将退出,但与上面的 exit 策略不同,它将由 bgworker 引擎自动重新启动,后者将在失败的同一批次上重试。它将继续退出并重新启动,直到错误得到解决。
skip¶
顾名思义,当处于 skip 错误策略中时,连接器工作器遇到的任何错误都不会导致工作器退出,但是错误消息仍将写入日志或 synchdb_state_view(),但连接器本身将忽略错误并继续处理下一个更改事件甚至下一个批次。
10) SPI Client¶
SPI Client 组件存在于 Replication Agent 下,它充当 PostgreSQL 核心和 SynchDB 之间的桥梁。它负责建立与 SPI 服务器的连接、启动事务、获取快照并执行由 DDL Converter 创建的给定 SQL 查询并销毁连接。对于要处理的每个查询,都会创建和销毁 SPI 连接,这似乎效率不高。由于 SPI 仅在 DDL 期间使用,而这通常不太频繁,因此在性能方面应该没问题。
11) 执行器 API¶
也驻留在复制代理中。此组件负责初始化执行器上下文、打开表、获取适当的锁、从 DML 转换器的输出创建 TupleTableSlot (TTS)、调用执行器 API 执行 INSERT、UPDATE、DELETE 操作并进行资源清理。这通常是一种比 SPI 更快的数据操作方法,因为它不需要像 SPI 那样解析输入查询字符串。
Debezium Runner 组件图¶
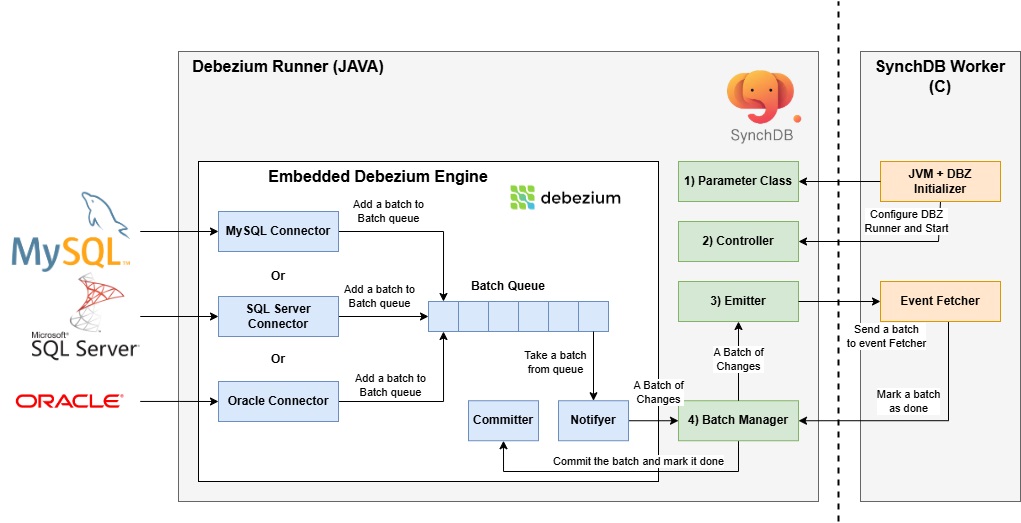
Debezium Runner 是 SynchDB 组件的一部分,位于部署的 Java 端。它是嵌入式 Debezium 引擎 (Java) 和 SynchDB Worker (C) 之间的主要促进者。它提供了 SynchDB Worker 可以通过 JNI 库进行交互的几种 Java 函数。这些交互包括初始化 Debezium 引擎、启动或停止引擎、获取一批更改事件以及将一批标记为已完成。这些操作对于确保复制一致性至关重要。主要组件包括:
- 参数配置
- 控制器
- 发射器
- 批处理管理器
1) 参数配置¶
参数配置表示一个 JAVA class结构,其中包含允许 SynchDB Worker 设置/获取参数值的公开参数和函数列表。这些参数会影响 Debezium Runner 和嵌入式 Debezium 的执行情况。这些参数也已暴露给 PostgreSQL GUC,以便 SynchDB Worker 可以调用相应的函数来设置参数值。这是目前将配置从基于 C 的 SynchDB Worker 传递到基于 JAVA 的 Debezium Runner 的唯一方法。
2) 控制器¶
控制器允许 SynchDB 启动或停止嵌入式 Debezium Engine。
3) 发射器¶
发射器表示由 SynchDB Worker 中的“事件获取器”组件定期调用的 JAVA 函数。它主要负责从“4) 批处理管理器”弹出batch,将其格式化为 JSON 事件列表作为字符串,并通过 JNI 将其返回到“事件获取器”。如果批处理管理器没有可用的batch,它将返回 NULL,并且“事件获取器”端不会发生任何处理。
4) 批处理管理器¶
批处理管理器主要负责接收来自嵌入式 Debezium 引擎的新批处理并将其存储在其内部队列中。此队列小得多,与组件图中嵌入式 Debezium 引擎内的批处理队列不同。当批处理管理器的内部队列已满时,节流阀控制将激活,以暂时停止来自 Debezium 端的事件生成,直到此小批处理队列有可用空间。只有当“发射器”收到来自“事件获取器”的获取请求并从批处理管理器弹出批处理时,才会从队列中取出批处理。
批处理管理器还为每个弹出的批处理分配一个批处理 ID,发送到发射器,最终发送到 SynchDB 工作器进行处理。此唯一 ID 与与其关联的“提交者”对象一起存储在其内部哈希表中。这些信息对于跟踪很重要。当 SynchDB 工作程序完成一个批次时,它将调用批次管理器中的“标记批次完成”方法,其中还包含相同的批次 ID,这有助于批次管理器查找相应的“提交者”对象。然后,提交者对象用于通知嵌入式 Debezium 引擎批次已完成,强制其提交并将其内部偏移量向前移动。这可确保在引擎重新启动的情况下不会再次处理同一个批次(不会重复)。